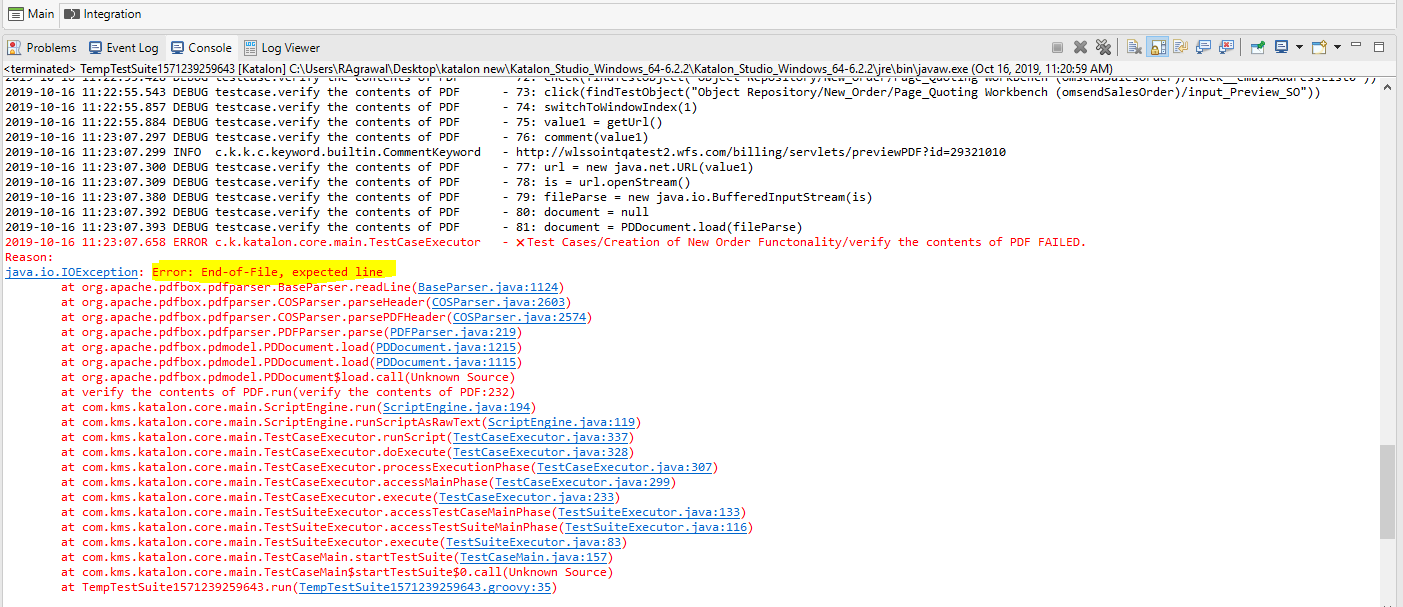
Hi Everyone i am getting End of File, expected Line Error. I am download the Jars through External Libraries in Katalon Studio. I am really new..Please help me…I am attaching the screenshot for the reference.
hi,
try to debug and print out what you are passing to PDFStripper
I am still getting End of File Error
hi,
and your debug results are?
Can you tell me the steps to debug because i dont know what i am doing correct or not.
Please…

hello,
was there any break point added? guess not
hi,
could you show what kind of .pdf url you are passing
like
“http://www.axmag.com/download/pdfurl-guide.pdf”
It is dynamic url, browser based.
http://wlssointqatest2.wfs.com/billing/servlets/previewPDF?id=29321015
the last id always keep on changing whenever you run the script.
hi,
oh that’s a reason, .pdf file is not read properly
are you able to download it first to your pc?
if yes then load it from path where it’s downloaded
I have changed the browser settings of PDF, now it is not opening in second Window, when i hit the Preview SO button i am able to download the PDF.
Can you show me the script where should i give this path in the code?
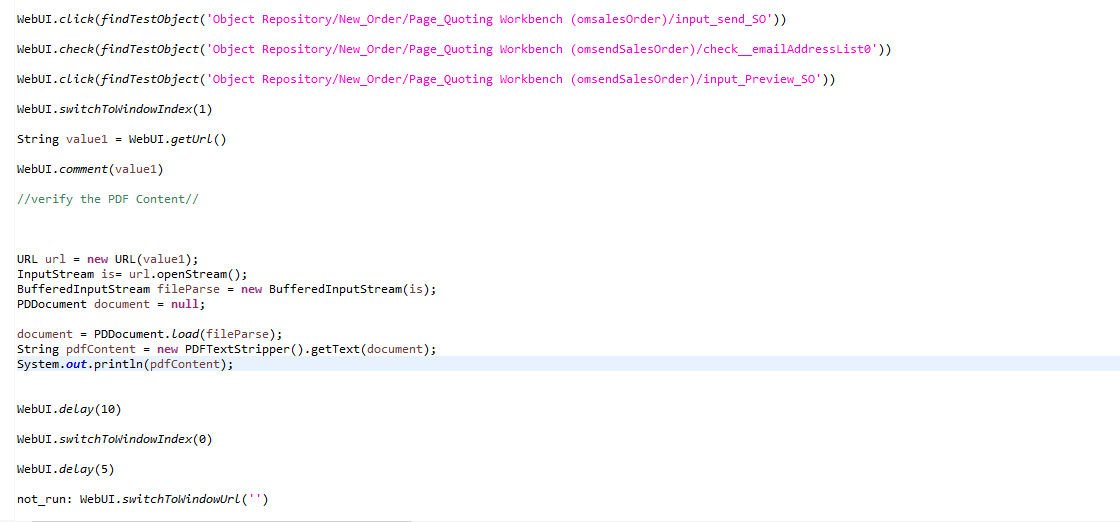
This is my code:
String value1 = WebUI.getUrl()
WebUI.comment(value1)
//verify the PDF Content//
URL url = new URL(value1);
InputStream is= url.openStream();
BufferedInputStream fileParse = new BufferedInputStream(is);
PDDocument document = null;
document = PDDocument.load(fileParse);
String pdfContent = new PDFTextStripper().getText(document);
System.out.println(pdfContent);
hello,
use FF or Chrome options to download it by runtime
example like this way (note this is not your solution)
public WebDriver setChromeOptions(File folder){
ChromeOptions options = new ChromeOptions();
String downloadPath = folder.getAbsolutePath()
//String downloadsPath = System.getProperty("user.home") + "/Downloads";
println ("downloadpath "+downloadPath)
Map<String, Object> chromePrefs = new HashMap<String, Object>()
chromePrefs.put("profile.default_content_settings.popups", 0);
chromePrefs.put("download.default_directory", downloadPath)
chromePrefs.put("download.prompt_for_download", false)
chromePrefs.put("plugins.plugins_disabled", "Chrome PDF Viewer");
options.addArguments("--headless")
options.addArguments("--window-size=1920,1080")
options.addArguments("--test-type")
options.addArguments("--disable-gpu")
options.addArguments("--no-sandbox")
options.addArguments("--disable-dev-shm-usage")
options.addArguments("--disable-software-rasterizer")
options.addArguments("--disable-popup-blocking")
options.addArguments("--disable-extensions")
options.setExperimentalOption("prefs", chromePrefs)
DesiredCapabilities cap = DesiredCapabilities.chrome()
cap.setCapability(ChromeOptions.CAPABILITY, options)
cap.setCapability(CapabilityType.ACCEPT_SSL_CERTS, true);
System.setProperty("webdriver.chrome.driver", DriverFactory.getChromeDriverPath())
WebDriver driver = new ChromeDriver(cap);
return driver
}I have changed the browser settings of PDF, now it is not opening in second Window, when i hit the Preview SO button i am able to download the PDF.
Can you show me the script where should i give this path in the code? Because the PDF File is going to be save on my Local Machine. How can i validate the contents of the PDF?
This is my code:
String value1 = WebUI.getUrl()
WebUI.comment(value1)
//verify the PDF Content//
URL url = new URL(value1);
InputStream is= url.openStream();
BufferedInputStream fileParse = new BufferedInputStream(is);
PDDocument document = null;
document = PDDocument.load(fileParse);
String pdfContent = new PDFTextStripper().getText(document);
System.out.println(pdfContent);
hi
in Chrome this line is where file is downloaded
chromePrefs.put(“download.default_directory”, downloadPath)
and
download it to the your project root like …/project/pdfFiles
My File is getting download in C:\Users\RAgrawal\Downloads
and Where should i add this Line chromePrefs.put(“download.default_directory”, downloadPath)…?
see my example how to use chrome options
I am not understanding where to write that Lines of code
ok,
if you are not got my point, then load file where it’s now downloaded
is file extension as .pdf in a download path?
example using method like this
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
import org.apache.pdfbox.text.PDFTextStripperByArea;
public List<String> openPfdFile(String pdfFile){
List<String> lines = new ArrayList<>()
//PDDocument pdfDocument = PDDocument.load(new File("C:/xxxx/xxxx/Desktop/data/file2.pdf"))
PDDocument pdfDocument = PDDocument.load(new File(pdfFile))
pdfDocument.getClass();
if (!pdfDocument.isEncrypted()) {
PDFTextStripperByArea pdfTextStripperByArea = new PDFTextStripperByArea();
pdfTextStripperByArea.setSortByPosition(Boolean.TRUE);
PDFTextStripper pdfTextStripper = new PDFTextStripper();
String pdfFileInText = pdfTextStripper.getText(pdfDocument);
lines = pdfFileInText.split("\\r?\\n");
for (String line : lines) {
System.out.println(line);
}
}
return lines
}Hi I have used this code as:
URL url = new URL(value1);
InputStream is= url.openStream();
BufferedInputStream fileParse = new BufferedInputStream(is);
//PDDocument document = null;
//document = PDDocument.load(fileParse);
//PDDocument pdfDocument = PDDocument.load(new File(“C:/Users/RAgrawal/Downloads/quote.pdf”))
PDDocument pdfDocument = PDDocument.load(new File(fileParse))
pdfDocument.getClass();
if (!pdfDocument.isEncrypted()) {
PDFTextStripperByArea pdfTextStripperByArea = new PDFTextStripperByArea();
pdfTextStripperByArea.setSortByPosition(Boolean.TRUE);
PDFTextStripper pdfTextStripper = new PDFTextStripper();
String pdfFileInText = pdfTextStripper.getText(pdfDocument);
lines = pdfFileInText.split("\\r?\\n");
for (String line : lines) {
System.out.println(line);
}
return lines
}
But i am getting the RunTime Exception as Could not find matching constructor for: java.io.File(java.io.BufferedInputStream)
at verify the contents of PDF.run(verify the contents of PDF:236)
at com.kms.katalon.core.main.ScriptEngine.run(ScriptEngine.java:194)
at com.kms.katalon.core.main.ScriptEngine.runScriptAsRawText(ScriptEngine.java:119)
at com.kms.katalon.core.main.TestCaseExecutor.runScript(TestCaseExecutor.java:337)
at com.kms.katalon.core.main.TestCaseExecutor.doExecute(TestCaseExecutor.java:328)
at com.kms.katalon.core.main.TestCaseExecutor.processExecutionPhase(TestCaseExecutor.java:307)
at com.kms.katalon.core.main.TestCaseExecutor.accessMainPhase(TestCaseExecutor.java:299)
at com.kms.katalon.core.main.TestCaseExecutor.execute(TestCaseExecutor.java:233)
at com.kms.katalon.core.main.TestSuiteExecutor.accessTestCaseMainPhase(TestSuiteExecutor.java:133)
at com.kms.katalon.core.main.TestSuiteExecutor.accessTestSuiteMainPhase(TestSuiteExecutor.java:116)
at com.kms.katalon.core.main.TestSuiteExecutor.execute(TestSuiteExecutor.java:83)
at com.kms.katalon.core.main.TestCaseMain.startTestSuite(TestCaseMain.java:157)
at com.kms.katalon.core.main.TestCaseMain$startTestSuite$0.call(Unknown Source)
at TempTestSuite1571255744088.run(TempTestSuite1571255744088.groovy:35)
hi,
“is” is reserved word in groovy use
InputStream inStrem= url.openStream();
BufferedInputStream fileParse = new BufferedInputStream(inStream);