@kazurayam @Russ_Thomas @grylion54
Hi Everyone,
I’m just reading through all the interesting responses (thank you again for your help). I think your observations and descriptions of the different functions behavior will be useful to everyone when planning an approach to writing Test Scripts. I’m going to try to read more about string manipulation (e.g. “String.contains()” today). It has been on my mind as in SQL there are ltrim, rtrim and trim functions.
I wanted to provide answers to the questions you all asked below:
This is what was in the console for the printf:
2020-08-20 08:43:23.547 DEBUG .2. Crawl Torontohousing Site Map - File - 3: println("This is the page title being tested: " + Test_Page_Title)
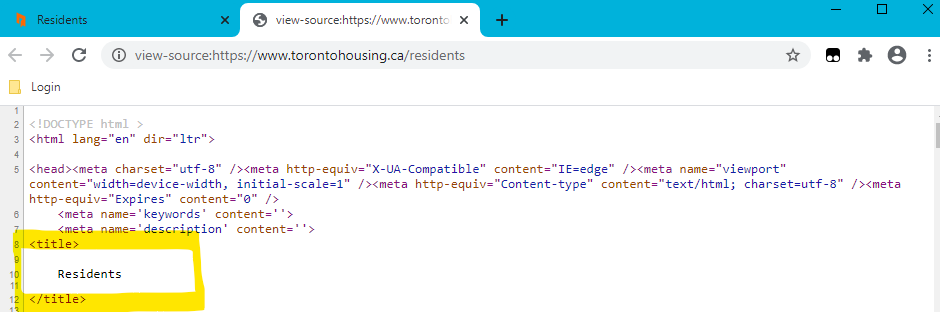
This is the page title being tested: Residents
This code which Russ suggested to use a Regex did work:
WebUI.verifyMatch(Test_Page_Title, ‘.Residents.’, true)
Remaining Problem:
The challenge seems to be applying the regex logic when you are comparing a page title in the attached Excel file with the actual page title retrieved via the “WebUI.getWindowTitle()” function.
Current Code Example which uses sample Excel file where Regex logic from Mikes Suggestion:
WebUI.enableSmartWait()
WebUI.openBrowser('')
WebUI.maximizeWindow()
WebUI.navigateToUrl(Test_Page_URL)
WebUI.delay(5)
assert WebUI.getUrl() == Test_Page_URL
println "This is the page title being tested: " + (Test_Page_Title)
WebUI.verifyMatch(WebUI.getWindowTitle(), ".*" + Test_Page_Title + ".*", true)
WebUI.closeBrowser()
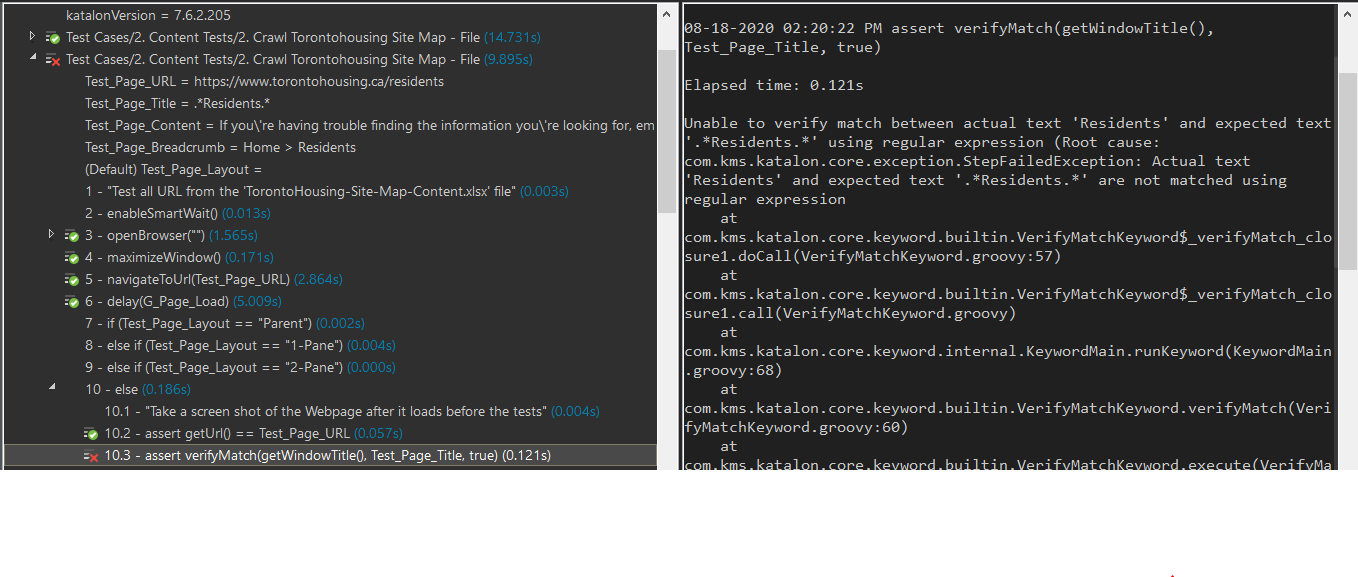
The Error this produces when referencing the ‘Residents’ page at URL Current tenants | Toronto Community Housing :
2020-08-20 09:48:09.362 DEBUG .2. Crawl Torontohousing Site Map - File - 4: verifyMatch(getWindowTitle(), “." + Test_Page_Title + ".”, true)
2020-08-20 09:48:09.471 ERROR c.k.k.core.keyword.internal.KeywordMain -  Unable to verify match between actual text ‘Residents’ and expected text ‘.Residents.’ using regular expression (Root cause: com.kms.katalon.core.exception.StepFailedException: Actual text ‘Residents’ and expected text ‘.Residents.’ are not matched using regular expression
Unable to verify match between actual text ‘Residents’ and expected text ‘.Residents.’ using regular expression (Root cause: com.kms.katalon.core.exception.StepFailedException: Actual text ‘Residents’ and expected text ‘.Residents.’ are not matched using regular expression
at com.kms.katalon.core.keyword.builtin.VerifyMatchKeyword$_verifyMatch_closure1.doCall(VerifyMatchKeyword.groovy:57)
at com.kms.katalon.core.keyword.builtin.VerifyMatchKeyword$_verifyMatch_closure1.call(VerifyMatchKeyword.groovy)
at com.kms.katalon.core.keyword.internal.KeywordMain.runKeyword(KeywordMain.groovy:68)
at com.kms.katalon.core.keyword.builtin.VerifyMatchKeyword.verifyMatch(VerifyMatchKeyword.groovy:60)
at com.kms.katalon.core.keyword.builtin.VerifyMatchKeyword.execute(VerifyMatchKeyword.groovy:45)
at com.kms.katalon.core.keyword.internal.KeywordExecutor.executeKeywordForPlatform(KeywordExecutor.groovy:73)
at com.kms.katalon.core.keyword.BuiltinKeywords.verifyMatch(BuiltinKeywords.groovy:73)
at 2. Crawl Torontohousing Site Map - File.run(2. Crawl Torontohousing Site Map - File:81)
at com.kms.katalon.core.main.ScriptEngine.run(ScriptEngine.java:194)
at com.kms.katalon.core.main.ScriptEngine.runScriptAsRawText(ScriptEngine.java:119)
at com.kms.katalon.core.main.TestCaseExecutor.runScript(TestCaseExecutor.java:339)
at com.kms.katalon.core.main.TestCaseExecutor.doExecute(TestCaseExecutor.java:330)
at com.kms.katalon.core.main.TestCaseExecutor.processExecutionPhase(TestCaseExecutor.java:309)
at com.kms.katalon.core.main.TestCaseExecutor.accessMainPhase(TestCaseExecutor.java:301)
at com.kms.katalon.core.main.TestCaseExecutor.execute(TestCaseExecutor.java:235)
at com.kms.katalon.core.main.TestSuiteExecutor.accessTestCaseMainPhase(TestSuiteExecutor.java:191)
at com.kms.katalon.core.main.TestSuiteExecutor.accessTestSuiteMainPhase(TestSuiteExecutor.java:141)
at com.kms.katalon.core.main.TestSuiteExecutor.execute(TestSuiteExecutor.java:90)
at com.kms.katalon.core.main.TestCaseMain.startTestSuite(TestCaseMain.java:157)
at com.kms.katalon.core.main.TestCaseMain$startTestSuite$0.call(Unknown Source)
at TempTestSuite1597931259844.run(TempTestSuite1597931259844.groovy:39)
TorontoHousing-Site-example.zip (11.5 KB)
Hopefully this will give a more through view of the issue being troubleshooted.
Part of the dilemma is where best to put the Regex text (e.g. in the Excel which was not working, perhaps Excel requires single quotation to indicate it is text in the cell which might throw things off).