I’m not familiar enough with Katalon Recorder to give you the statements, however, if product = '2022/11/26 土曜日~2022/11/29 火曜日 にお届け'
then product.split("\\~")[1] will give you the sentence after the tilde (e.g. ~). The result of the “split()” is an List of Strings, but with the “[1]”, the result is just a String.
And product.split("\\~")[0] will give you the sentence before the tilde.
Edit: Also note that you should escape the tilde with the slashes as the “split()” command expects a RegEx within the parentheses and the tilde is a RegEx character, but you don’t want it to be in this case.
@akiganai
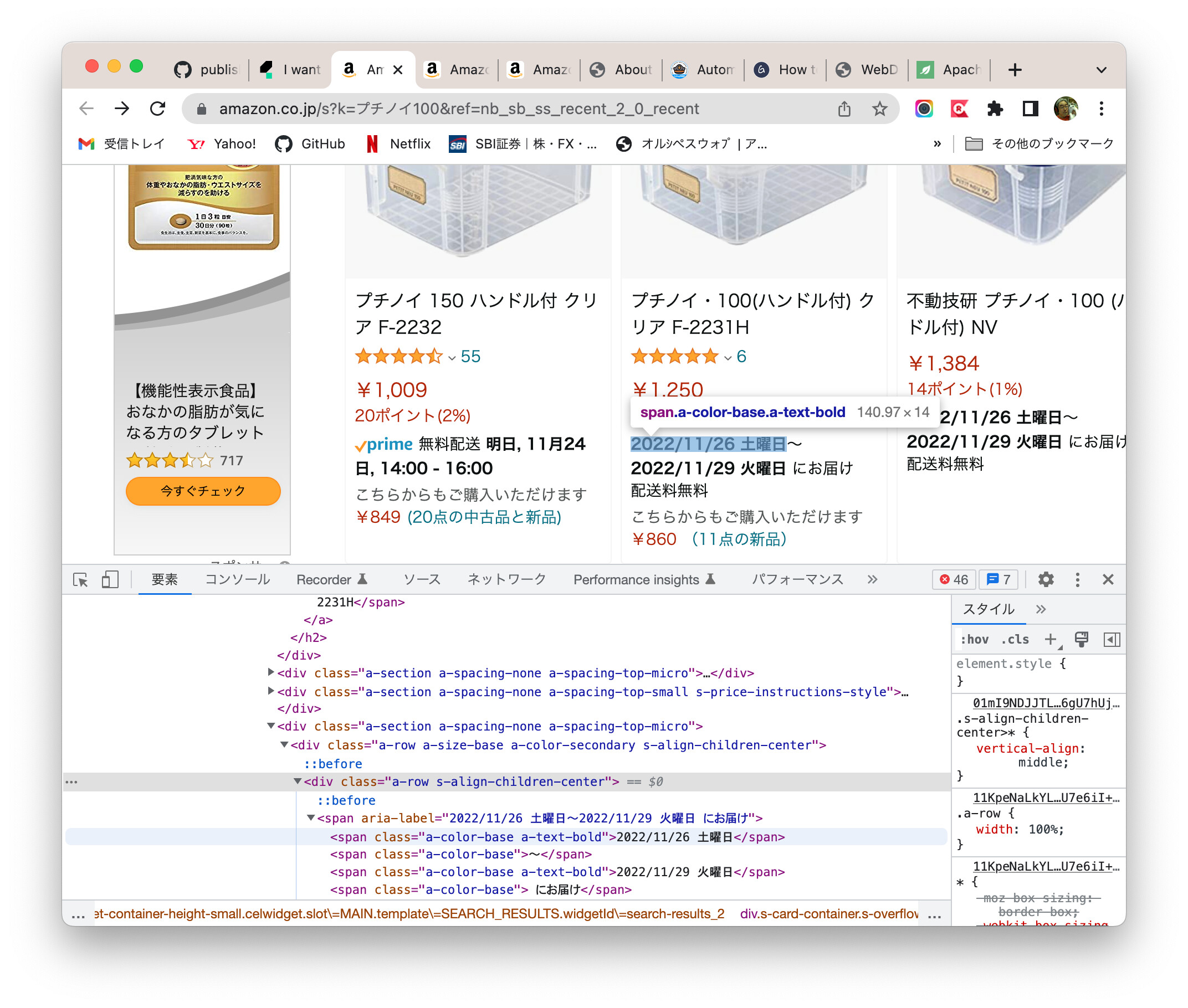
You used the following XPath to locate the <span> element of the product named “プチノイ・100(ハンドル付) クリア F-2231H”
This XPath is very fragile. It will easily break and stop working when the content of the target web page is changed in near future to have more or less products and the <div> of products are rearranged.
I am sure, you would rather like to use a XPath (or CSS selector) that identifies the target HTML element by the displayed text “プチノイ・100(ハンドル付) クリア F-2231H”.
However, tools like Katalon Recorder and Katalon Studio’s Recorder & Spy can not generate such XPaths with predicates by content text. Tools would not be helpful enough. You need to be able to write good XPaths manually yourself.
I mean, you have to study XPath technology first. In order to learn XPath applied to the Selenium-base ui testings, read the following article
Especially, you woud want the predicates wike //div[contains(. , "プチノイ" and contains(. ,"F-2231H"))
@grylion54 already told you how to write a JavaScript to do what you want.
Perhaps you need to learn how to use Katalon Recorder and execute a JavaScript in it.
I am sorry I do not know Karalon Recorder either. I can not tell you how to use KR.
I find that Katalon Recorder does not provide good documentation for beginners (it is the reason why I do not know KR yet). → @vu.tran any comment?
Perhaps, you should rather start with Selenium IDE, of which Katalon Recorder is said to be compatible. If you search Google for “Selenium IDE” you would find some good “tutorial” articles. For example,
Just for my interest, I wrote a Test Case script in Katalon Studio. This code does the following.
open browser, visit a URL https://www.amazon.co.jp/s?k=プチノイ100&ref=nb_sb_ss_recent_2_0_recent 1
in the page, identify the HTML element of the product with name that contains text fragment プチノイ and F-2231H
and further search the HTML element of the “delivery date range from” of that product; get the text. The text will be for example “2022/11/26 土曜日”.
convert the date text to a java.time.LocalDate instance
verify if the “delivery date range from” is earlier than the date 7 days after today. If it is, the test passes; otherwise the test fails.
import java.time.LocalDate
import java.time.format.DateTimeFormatter
import com.kms.katalon.core.testobject.ConditionType
import com.kms.katalon.core.testobject.TestObject
import com.kms.katalon.core.util.KeywordUtil
import com.kms.katalon.core.webui.keyword.WebUiBuiltInKeywords as WebUI
TestObject makeTestObject(String xpath) {
TestObject tObj = new TestObject(xpath)
tObj.addProperty("xpath", ConditionType.EQUALS, xpath)
return tObj
}
String url = "https://www.amazon.co.jp/s?k=プチノイ100&ref=nb_sb_ss_recent_2_0_recent 1"
WebUI.openBrowser(url)
// make sure the page is completely loaded
String xpBaseDiv = "//div[contains(., 'プチノイ') and (contains(., 'F-2231H'))]"
WebUI.verifyElementPresent(makeTestObject(xpBaseDiv), 10)
// get the text of "date range from" of the product "プチノイ・100(ハンドル付) クリア F-2231H"
String fromDateLocator = """
${xpBaseDiv}
//following-sibling::div[3]
//span[@aria-label]/span[1]
"""
WebUI.waitForElementPresent(makeTestObject(fromDateLocator), 5)
String rangeFromStr = WebUI.getText(makeTestObject(fromDateLocator)) // e.g, "2022/11/26 土曜日"
WebUI.comment("rangeFromStr=${rangeFromStr}")
// convert the "2022/11/26 土曜日" text into a java.time.LocateDate instance
DateTimeFormatter dtf = DateTimeFormatter.ofPattern("uuuu/MM/dd EEEE", Locale.JAPANESE)
LocalDate rangeFromLocalDate = LocalDate.parse(rangeFromStr, dtf)
WebUI.comment("rangeFromLocalDate=${DateTimeFormatter.ISO_LOCAL_DATE.format(rangeFromLocalDate)}")
// verify if the rangeFromLocalDate is within 1 week from today
LocalDate deadline = LocalDate.now().plusDays(7)
if (rangeFromLocalDate.isBefore(deadline)) {
WebUI.comment("rageFromLocalDate is before the deadline=${deadline}");
} else {
KeywordUtil.markFailedAndStop("rangeFromLocalDate is NOT before the deadline=${deadline}");
}
WebUI.closeBrowser()
This test proved that the “delivery date range from” of the target product is 2022/11/26, and it is before the day that is 7 days after today (2022/11/30).
I hope @akiganai can see how far we can go using automated UI tests.
There could be possibly many people who are using KR for their tasks, though I do not know how many.
But, i am sure that there aren’t many KR users (may be none?) who visit this site frequently and are willing to send replies to the questions about KR.
The frequent visitors here (including me) are users of Katalon Studio.
Thank you for your good question. Your question was good because
You shared the URL in question: https://www.amazon.co.jp/… , so that I could easily understand what you wanted to do. It enabled me to look at the URL in question using browsers DevTool and study the HTML in detail.
Most of the questions to this forum do not share the URL in question. These questions are difficult simply because I can not see the URL on my machine.
The quetioners often write “I can not share the URL due to security reasons” or “the site is hosted in our private network”. Oh, how they are lazy! They do not prepare their questions understandable for others!
You shared the XPath in question: //div[@id=‘search’]/div/div/div/… , so that I could easily see that
possibly you relied on the testing tools (KR for you) to generate it
possibly you do not know XPath technology
Therefore I could make some comments to tell how to study the basic technologies you need to learn.
You stated clearly what you wanted to do: “I want to extract sentences after(or before)“~”(2022/11/26 土曜日or2022/11/29 火曜日 にお届け)”.
Some posts in this forum do not state their questions clearly. They tend to use ambiguous words, for example “I want Katalon to integrate XXX” without any concrete detail. That’s too bad.
Don’t mind. Your question was good. I enjoyed it. Thanks.